正規表現を使うと、いろいろなテキスト処理が可能になるので、便利だ。
例えば、HTMLファイルのタグをすべて取り除き、テキストのみにすることもできる。
今回は、HTMLファイルのタグを取り除く正規表現を紹介したい。
正規表現を使ってHTMLファイルのタグを取り除く
テキストエディター Mery の起動
テキストエディターの Mery を起動する。
Mery については、以下を参照。

【ツール】正規表現も使える無料テキストエディター「Mery」の紹介!
以下の記事で正規表現をご紹介したが、正規表現が使えるテキストエディターがあれば便利だ。今回は、無料で使えるテキストエディター、「Mery」という便利なソフトを紹介したい。「Mery」のインストール方法以下から、「無料ダウンロード」をクリック...
wadohack.main-path.com
2025.12.05
テキストエディター Mery での処理
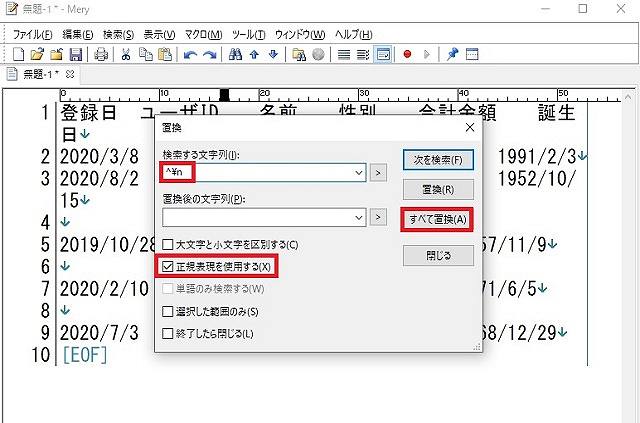
htmlコードのサンプルとして、以下の html コードを Mery に貼り付ける。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>正規表現</title>
</head>
<body>
エスケープ文字とは?
</body>
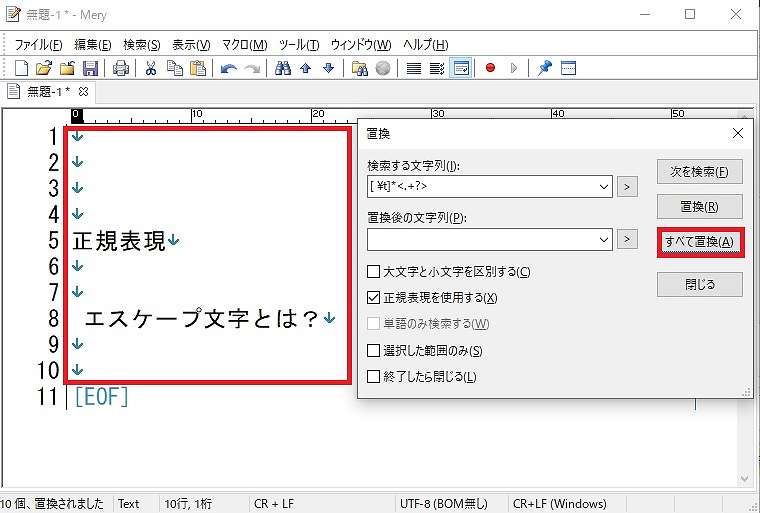
</html>貼り付けたあと、ショートカットの「Ctrl」+「R」キーで検索置換画面を表示させる。
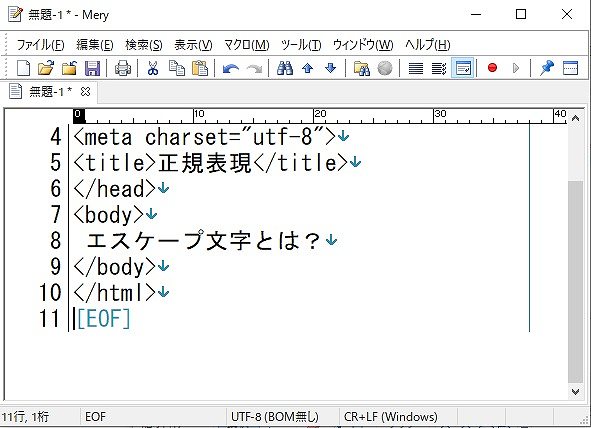
検索置換画面の設定で、「正規表現を使用する」にチェック (✓) が入っていることを確認してから、「検索する文字列」の下のテキストボックスに、「 [ \t]*<.+?>」を入力し、「置換後の文字列」は、空欄のまま (つまり、置換後は、削除されることを意味する) にする。
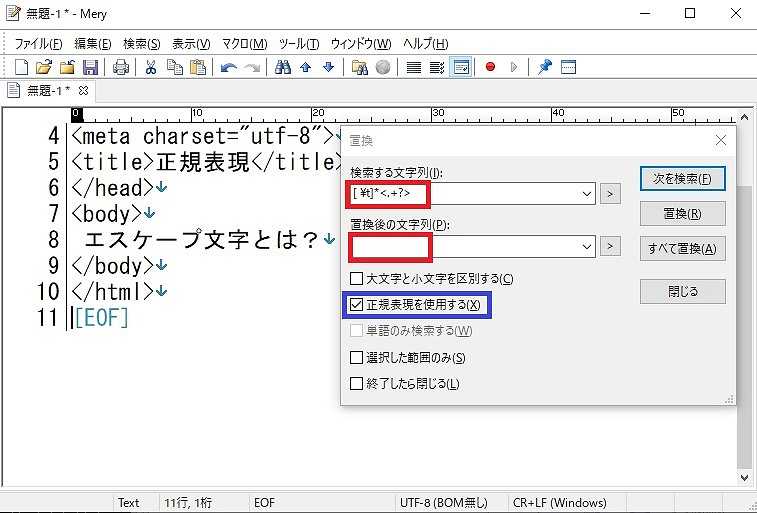
置換する前に、念のため、タグのみが検索されているか確認するために、「次を検索」ボタンを押すと、タグのみがハイライトされた。
このあと、「すべて置換」ボタンを押すと、テキストエディターのタグがすべて削除され、テキストのみが残った。
コメント